DeepSeek, das chinesische KI-Labor, hat mit seinen neuesten Modellen DeepSeek-V3 und DeepSeek-R1 nicht nur die KI-Landschaft, sondern auch die Tech-Börse zum Beben gebracht. Beide Modelle setzen neue Maßstäbe in Bezug auf Effizienz, Leistung und Innovation. Während DeepSeek V3 mit seinem 8-Bit-Training und der Mixture-of-Experts-Architektur glänzt, hebt sich DeepSeek-R1 durch den DeepThink-Modus hervor, der speziell für komplexe logische und mathematische Aufgaben entwickelt wurde.
Dieser Headline-Blogbeitrag verbindet die technischen Aspekte beider Modelle und beleuchtet, warum sie gemeinsam die Zukunft der KI prägen.
Die technische Überlegenheit von DeepSeek V3
8-Bit-Training: Effizienz durch reduzierte Präzision
DeepSeek V3 nutzt FP8-Mixed-Precision-Training, eine Technik, die den Speicherbedarf um 30 % reduziert und gleichzeitig die Rechenleistung optimiert. Im Vergleich zu herkömmlichen FP16-Modellen wie ChatGPT ermöglicht dies eine schnellere Verarbeitung großer Datenmengen bei geringerem Energieverbrauch. Dies ist besonders wichtig für die Skalierbarkeit und Nachhaltigkeit von KI-Modellen .
Mixture-of-Experts: Spezialisierung durch multiple Experten
Die MoE-Architektur von DeepSeek V3 besteht aus 671 Milliarden Parametern, von denen jeweils nur 37 Milliarden aktiviert werden. Dies ermöglicht eine spezialisierte Aufgabenbearbeitung, bei der für jede Anfrage die relevanten „Experten“ im Modell aktiviert werden. Im Gegensatz zu dichten Modellen wie ChatGPT, die alle Parameter für jede Aufgabe nutzen, spart dies erhebliche Rechenressourcen und verbessert die Effizienz .
Reinforcement Learning: Lernen durch Interaktion
DeepSeek V3 setzt auf Reinforcement Learning (RL), um seine Fähigkeiten kontinuierlich zu verbessern. Im Gegensatz zu ChatGPT, das auf überwachtes Fein-Tuning angewiesen ist, lernt DeepSeek V3 durch direkte Interaktion mit Benutzern und passt seine Antworten dynamisch an. Dies führt zu einer höheren Anpassungsfähigkeit und einer menschlicheren Denkweise .
DeepSeek-R1 und der DeepThink-Modus: Das ist mal eine echte Innovation für komplexe Aufgaben
DeepThink-Modus: Transparenz und Effizienz
Der DeepThink-Modus ist ein Schlüsselmerkmal von DeepSeek-R1, das es von anderen Modellen wie GPT-4 oder Claude abhebt. Dieser Modus ermöglicht es dem Modell, komplexe Probleme durch lange Denkketten (Chain-of-Thought, CoT) zu lösen, die oft mehrere tausend Wörter umfassen. Dabei wird jeder Schritt des Denkprozesses, einschließlich Reflexion und Verifikation, detailliert dargestellt. Dies führt zu einer höheren Genauigkeit und einer besseren Nachvollziehbarkeit der Ergebnisse .
Reinforcement Learning ohne Supervised Fine-Tuning
DeepSeek-R1 nutzt Reinforcement Learning (RL) als primären Trainingsmechanismus, ohne auf Supervised Fine-Tuning (SFT) zurückzugreifen. Dies ermöglicht es dem Modell, eigenständig Denkmuster zu entwickeln und komplexe Probleme durch Chain-of-Thought (CoT) zu lösen. Diese Methode hat sich als äußerst effektiv erwiesen, insbesondere in Bereichen wie mathematischer Logik und Code-Generierung .
Mixture-of-Experts Architektur
Auch DeepSeek-R1 basiert auf einer Mixture-of-Experts-Architektur mit 671 Milliarden Parametern, von denen jeweils nur 37 Milliarden aktiviert werden. Diese Architektur spart Rechenressourcen und verbessert die Effizienz erheblich, insbesondere bei spezialisierten Aufgaben .
Vergleich mit anderen Modellen
DeepSeek V3 vs. GPT-4
DeepSeek V3 übertrifft GPT-4 in vielen Bereichen, insbesondere bei spezialisierten Aufgaben wie Code-Generierung und mathematischer Logik. Tests zeigen, dass DeepSeek V3 komplexe Programmieraufgaben effizienter löst und präzisere Ergebnisse liefert .
Das besondere dabei, die API Token-Kosten sind um ein vielfaches geringer. Wenn wir es mit ChatGPT vergleichen, dann sieht es so aus: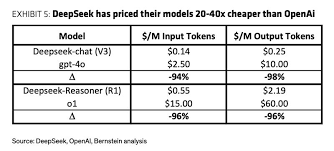
DeepSeek-R1 vs. Claude-3.5
Während Claude-3.5 in einigen Bereichen wie der Sprachverarbeitung stark ist, zeigt DeepSeek-R1 eine überlegene Leistung bei Aufgaben, die lange Denkketten und detaillierte Verifikation erfordern. Dies macht es besonders nützlich für Anwendungen in der Wissenschaft und Technik .
Anwendungsfälle und Potenzial
Bildung und Forschung
Der DeepThink-Modus von DeepSeek-R1 eignet sich ideal für den Einsatz in der Bildung, da er Schülern und Studenten dabei hilft, komplexe mathematische und logische Probleme zu verstehen. Die detaillierte Darstellung des Denkprozesses fördert das Lernen und die kritische Denkfähigkeit .
Softwareentwicklung
In der Softwareentwicklung können sowohl DeepSeek V3 als auch DeepSeek-R1 bei der Code-Generierung, Fehlerbehebung und Algorithmus-Optimierung eingesetzt werden. Die Fähigkeit, lange Denkketten zu generieren, macht DeepSeek-R1 besonders nützlich für komplexe Programmieraufgaben .
Wissenschaftliche Forschung
Beide Modelle können in der wissenschaftlichen Forschung eingesetzt werden, um komplexe Datenanalysen und logische Schlussfolgerungen zu unterstützen. Die Transparenz des DeepThink-Modus ermöglicht es Forschern, die Ergebnisse besser zu verstehen und zu validieren .
Herausforderungen und zukünftige Entwicklungen
Inkonsistenzen in der Modellausgabe
Trotz ihrer beeindruckenden Leistung gibt es Berichte über gelegentliche Inkonsistenzen in den Antworten von DeepSeek V3 und DeepSeek-R1. Dies könnte auf die komplexe MoE-Architektur oder unvollständige Trainingsdaten zurückzuführen sein .
Zukünftige Entwicklungen
DeepSeek plant, die Modelle vollständig zu open-sourcen und APIs für die breite Nutzung bereitzustellen. Dies wird voraussichtlich zu einer weiteren Verbesserung der Leistung und einer breiteren Anwendung der Modelle führen .
Unser Fazit:
Künstliche Intelligenz steht noch am Anfang. Von KI QR-Code Generator bis hin zu Optimierung der Produktionsprozessen ist das Thema weit gefächert.
DeepSeek V3 und DeepSeek-R1 zeigen, dass die Zukunft der KI effizienter, leistungsfähiger und nachhaltiger sein wird als bisher angenommen. Mit viel geringeren Kosten kann dabei ein Vielfaches an Leistung erreicht werden. Diese Entwicklungen werden nicht nur die KI-Landschaft verändern, sondern auch neue Möglichkeiten für Bildung, Forschung und Industrie eröffnen.
Interessiert an weiteren Headline Blogbeiträgen der Nelpx GmbH? Dann abonniere kostenlos unseren Newsletter!